中文分词方法(搜索引擎常用的中文分词的方法)
1.搜索引擎常用的中文分词的方法有哪些
1. 分词是指将一段句子切分成一个个单独的词项,对于英文来讲,单词作为词项,由于英文的书写格式,词与词之间必须有空格,这样搜索引擎很容易将一段句子处理成词项的集合;但是中文来讲,词之间没有空格,搜索引擎不能够直接将句子处理成词项的集合,需要一个分词过程,这里简单介绍搜索引擎中文分词的方法。
一、基于词典的分词方法
也叫“机械分词法”,将分词的句子与词典中的词语进行匹配,如果匹配成功,则将匹配的部分作为一个词,最后生成一个词语序列,根据分词的方向与优先长度不同可分为一下四种方法:
1、正向匹配法
根绝句子的正序(由左至右)进行匹配,例如:发展中国家,切分为:发展/中国/家。
2、逆向匹配法
根据句子的逆序(由右至左)进行匹配,例如:发展中国家,切分为:发展/中/国家。
3、最大匹配法
根据词典中最长的词语的长度确切分,如果不是,则在使用次一级长度去切分,假设字典中最长的词语是4个,以“发展中国家”为例,首先截取前四个“发展中国”判断,如果与字典中的词匹配,那么就是词项,如果不匹配,那就截取前三个词“发展中”来判断,以此类推直至切分出词项。
4、最小匹配法
同最大匹配法刚好相反。
二、基于理解分词的方法
为了解决分词中的歧义问题,搜索引擎完全模拟人理解句子的过程,对句子进行句法分析与语义分析,这个方法需要大量的语言知识和信息,计算过程比较复杂,对搜索引擎的基础硬件要求比较高。
三、基于统计分词的方法
随着时代与互联网的发展,会产生很多新的词汇,例如一些人名、新科技名词、新事件名(比如XX门、XX帝等),这些词汇未被词典收录,这些词成为“未登录词”,这些词汇的切分就要依靠统计分词的方法,搜索引擎通过统计这些字在整个语料库中出现的频率,例如在语料库中发现“S”、“E”、“O”同时出现的次数非常高,那么搜索引擎就判定”SEO”是一个词汇。
2.中文分词的常见项目
功能性能 功能描述:1.新词自动识别 对词典中不存在的词,可以自动识别,对词典的依赖较小;2.词性输出 分词结果中带有丰富的词性;3.动态词性输出 分词结果中的词性并非固定,会根据不同的语境,赋予不同的词性;4.特殊词识别 比如化学、药品等行业词汇,地名、品牌、媒体名等;5.智能歧义解决 根据内部规则,智能解决常见分词歧义问题;6.多种编码识别 自动识别各种单一编码,并支持混合编码;7.数词量词优化 自动识别数量词; 性能介绍:处理器:AMD Athlon II x2 250 3GHZ 单线程大于833KB/s,多线程安全。
一个PHP函数实现中文分词。使分词更容易,使用如下图: Paoding(庖丁解牛分词)基于Java的开源中文分词组件,提供lucene和solr 接口,具有极 高效率和 高扩展性。
引入隐喻,采用完全的面向对象设计,构思先进。高效率:在PIII 1G内存个人机器上,1秒可准确分词 100万汉字。
采用基于 不限制个数的词典文件对文章进行有效切分,使能够将对词汇分类定义。能够对未知的词汇进行合理解析。
仅支持Java语言。 MMSEG4J基于Java的开源中文分词组件,提供lucene和solr 接口:1.mmseg4j 用 Chih-Hao Tsai 的 MMSeg 算法实现的中文分词器,并实现 lucene 的 analyzer 和 solr 的TokenizerFactory 以方便在Lucene和Solr中使用。
2.MMSeg 算法有两种分词方法:Simple和Complex,都是基于正向最大匹配。Complex 加了四个规则过虑。
官方说:词语的正确识别率达到了 98.41%。mmseg4j 已经实现了这两种分词算法。
盘古分词是一个基于.net 平台的开源中文分词组件,提供lucene(.net 版本) 和HubbleDotNet的接口 高效:Core Duo 1.8 GHz 下单线程 分词速度为 390K 字符每秒 准确:盘古分词采用字典和统计结合的分词算法,分词准确率较高。功能:盘古分词提供中文人名识别,简繁混合分词,多元分词,英文词根化,强制一元分词,词频优先分词,停用词过滤,英文专名提取等一系列功能。
jcseg是使用Java开发的一个中文分词器,使用流行的mmseg算法实现。 1。
mmseg四种过滤算法,分词准确率达到了98.4%以上。2。
支持自定义词库。在lexicon文件夹下,可以随便添加/删除/更改词库和词库内容,并且对词库进行了分类,词库整合了《现代汉语词典》和cc-cedict辞典。
3。词条拼音和同义词支持,jcseg为所有词条标注了拼音,并且词条可以添加同义词集合,jcseg会自动将拼音和同义词加入到分词结果中。
4。中文数字和分数识别,例如:"四五十个人都来了,三十分之一。
"中的"四五十"和"三十分之一",并且jcseg会自动将其转换为对应的阿拉伯数字。5。
支持中英混合词的识别。例如:B超,x射线。
6。支持基本单字单位的识别,例如2012年。
7。良好的英文支持,自动识别电子邮件,网址,分数,小数,百分数……。
8。智能圆角半角转换处理。
9。特殊字母识别:例如:Ⅰ,Ⅱ10。
特殊数字识别:例如:①,⑩11。配对标点内容提取:例如:最好的Java书《java编程思想》,‘畅想杯黑客技术大赛’,被《,‘,“,『标点标记的内容。
12。智能中文人名识别。
中文人名识别正确率达94%以上。jcseg佩带了jcseg.properties配置文档,使用文本编辑器就可以自主的编辑其选项,配置适合不同应用场合的分词应用。
例如:最大匹配分词数,是否开启中文人名识别,是否载入词条拼音,是否载入词条同义词……。 friso是使用c语言开发的一个中文分词器,使用流行的mmseg算法实现。
完全基于模块化设计和实现,可以很方便的植入到其他程序中,例如:MySQL,PHP等。并且提供了一个php中文分词扩展robbe。
1。只支持UTF-8编码。
【源码无需修改就能在各种平台下编译使用,加载完20万的词条,内存占用稳定为14M。】。
2。mmseg四种过滤算法,分词准确率达到了98.41%。
3。支持自定义词库。
在dict文件夹下,可以随便添加/删除/更改词库和词库词条,并且对词库进行了分类。4。
词库使用了friso的Java版本jcseg的简化词库。5。
支持中英混合词的识别。例如:c语言,IC卡。
7。很好的英文支持,电子邮件,网址,小数,分数,百分数。
8。支持阿拉伯数字基本单字单位的识别,例如2012年,5吨,120斤。
9。自动英文圆角/半角,大写/小写转换。
并且具有很高的分词速度:简单模式:3.7M/秒,复杂模式:1.8M/秒。
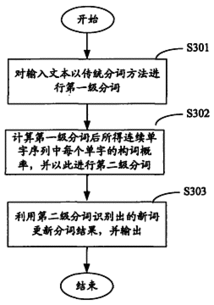
3.有哪些比较好的中文分词方案
1.每次从一个完整的句子里,按照从左向右的顺序,识别出多种不同的3个词的组合;然后根据下面的4条消歧规则,确定最佳的备选词组合;选择备选词组合中的第1个词,作为1次迭代的分词结果;剩余的2个词继续进行下一轮的分词运算。采用这种办法的好处是,为传统的前向最大匹配算法加入了上下文信息,解决了其每次选词只考虑词本身,而忽视上下文相关词的问题。4条消歧规则包括,
1)备选词组合的长度之和最大。
2)备选词组合的平均词长最大;
3)备选词组合的词长变化最小;
4)备选词组合中,单字词的出现频率统计值最高。
CRF方法是目前公认的效果最好的分词算法。但,具体效果是否好,也依赖于你使用的训练模型。
4.百度中文分词如何分词
而百度中文分词就是把词按照一定的规格,将一个长尾词分割成几个部分,从而概括一段话的主要内容。
在百度中文分词中,百度强调的是:一、字符串匹配的分词方法。我们需要有一定的字符串做基础,就是一段词用字符分开,比如标点符号,空格等。
才能够进行分词匹配,我们把这些字符串叫做机械词典。机械词典的个数不定。
由每个搜索引擎自己确定。每个机械词典之间还会有优先级。
字符串匹配的分词方法最常用的有几种:1、正向最大匹配法(由左到右的方向)2、逆向最大匹配法(由右到左的方向)3、最少切分(使每一句中切出的词数最小)百度中文分词基于字符串匹配举例给大家说明一下:“我想去澳大利亚旅游”正向最大匹配:我想去,澳大利亚旅游逆向最大匹配:我想,想去,澳大利亚,旅游。最少切分:我把上面哪句话分成的词要是最少的“我想去,澳大利亚旅游”这就是最短路径分词法,分出来就只有2个词了。
另外,不同的搜索的词典不同,分出来的词也不同。二、理解的分词方法。
这种分词方法不需要机械词典。这种其实就是一种机器语音判断的分词方法。
很简单,进行句法、语义分析,利用句法信息和语义信息来处理歧义现象来分词,这种分词方法,现在还不成熟。处在测试阶段。
三、统计的分词方法。这个顾名思义,就是根据词组的统计,发现那些相邻的字出现的频率高,那么这个词就很重要。
可以作为用户提供字符串中的分隔符。比如,“我的,你的,许多的,这里,这一,那里”。
等等,这些词出现的比较多,就从这些词里面分开来。四、对于百度中文分词的理解:基于统计的分词方法得到的词或者句子的权重要高于基于字符串匹配得到的。
就是全字匹配得到的词的权重会高于分开的词的权重。根据自己的观察现在百度大部分都是使用的是正向匹配。
百度分词对于一句话分词之后,还会去掉句子中的没有意义的词语。
5.什么是中文分词
中文分词技术属于自然语言处理技术范畴,对于一句话,人可以通过自己的知识来明白哪些是词,哪些不是词,但如何让计算机也能理解?其处理过程就是分词算法。
现有的分词算法可分为三大类:基于字符串匹配的分词方法、基于理解的分词方法和基于统计的分词方法。 1、基于字符串匹配的分词方法 这种方法又叫做机械分词方法,它是按照一定的策略将待分析的汉字串与一个“充分大的”机器词典中的词条进行配,若在词典中找到某个字符串,则匹配成功(识别出一个词)。
按照扫描方向的不同,串匹配分词方法可以分为正向匹配和逆向匹配;按照不同长度优先匹配的情况,可以分为最大(最长)匹配和最小(最短)匹配;按照是否与词性标注过程相结合,又可以分为单纯分词方法和分词与标注相结合的一体化方法。常用的几种机械分词方法如下: 1)正向最大匹配法(由左到右的方向); 2)逆向最大匹配法(由右到左的方向); 3)最少切分(使每一句中切出的词数最小)。
还可以将上述各种方法相互组合,例如,可以将正向最大匹配方法和逆向最大匹配方法结合起来构成双向匹配法。由于汉语单字成词的特点,正向最小匹配和逆向最小匹配一般很少使用。
一般说来,逆向匹配的切分精度略高于正向匹配,遇到的歧义现象也较少。统计结果表明,单纯使用正向最大匹配的错误率为1/169,单纯使用逆向最大匹配的错误率为1/245。
但这种精度还远远不能满足实际的需要。实际使用的分词系统,都是把机械分词作为一种初分手段,还需通过利用各种其它的语言信息来进一步提高切分的准确率。
一种方法是改进扫描方式,称为特征扫描或标志切分,优先在待分析字符串中识别和切分出一些带有明显特征的词,以这些词作为断点,可将原字符串分为较小的串再来进机械分词,从而减少匹配的错误率。另一种方法是将分词和词类标注结合起来,利用丰富的词类信息对分词决策提供帮助,并且在标注过程中又反过来对分词结果进行检验、调整,从而极大地提高切分的准确率。
对于机械分词方法,可以建立一个一般的模型,在这方面有专业的学术论文,这里不做详细论述。 2、基于理解的分词方法 这种分词方法是通过让计算机模拟人对句子的理解,达到识别词的效果。
其基本思想就是在分词的同时进行句法、语义分析,利用句法信息和语义信息来处理歧义现象。它通常包括三个部分:分词子系统、句法语义子系统、总控部分。
在总控部分的协调下,分词子系统可以获得有关词、句子等的句法和语义信息来对分词歧义进行判断,即它模拟了人对句子的理解过程。这种分词方法需要使用大量的语言知识和信息。
由于汉语语言知识的笼统、复杂性,难以将各种语言信息组织成机器可直接读取的形式,因此目前基于理解的分词系统还处在试验阶段。 3、基于统计的分词方法 从形式上看,词是稳定的字的组合,因此在上下文中,相邻的字同时出现的次数越多,就越有可能构成一个词。
因此字与字相邻共现的频率或概率能够较好的反映成词的可信度。可以对语料中相邻共现的各个字的组合的频度进行统计,计算它们的互现信息。
定义两个字的互现信息,计算两个汉字X、Y的相邻共现概率。互现信息体现了汉字之间结合关系的紧密程度。
当紧密程度高于某一个阈值时,便可认为此字组可能构成了一个词。这种方法只需对语料中的字组频度进行统计,不需要切分词典,因而又叫做无词典分词法或统计取词方法。
但这种方法也有一定的局限性,会经常抽出一些共现频度高、但并不是词的常用字组,例如“这一”、“之一”、“有的”、“我的”、“许多的”等,并且对常用词的识别精度差,时空开销大。实际应用的统计分词系统都要使用一部基本的分词词典(常用词词典)进行串匹配分词,同时使用统计方法识别一些新的词,即将串频统计和串匹配结合起来,既发挥匹配分词切分速度快、效率高的特点,又利用了无词典分词结合上下文识别生词、自动消除歧义的优点。
到底哪种分词算法的准确度更高,目前并无定论。对于任何一个成熟的分词系统来说,不可能单独依靠某一种算法来实现,都需要综合不同的算法。
笔者了解,海量科技的分词算法就采用“复方分词法”,所谓复方,相当于用中药中的复方概念,即用不同的药材综合起来去医治疾病,同样,对于中文词的识别,需要多种算法来处理不同的问题。 分词中的难题 有了成熟的分词算法,是否就能容易的解决中文分词的问题呢?事实远非如此。
中文是一种十分复杂的语言,让计算机理解中文语言更是困难。在中文分词过程中,有两大难题一直没有完全突破。
1、歧义识别 歧义是指同样的一句话,可能有两种或者更多的切分方法。例如:表面的,因为“表面”和“面的”都是词,那么这个短语就可以分成“表面 的”和“表 面的”。
这种称为交叉歧义。像这种交叉歧义十分常见,前面举的“和服”的例子,其实就是因为交叉歧义引起的错误。
“化妆和服装”可以分成“化妆 和 服装”或者“化妆 和服 装”。由于没有人的知识去理解,计算机很难知道到底哪个方案正确。
交叉歧义相对组合歧义来说是还算比较容易处理,组。
6.中文分词的应用
在自然语言处理技术中,中文处理技术比西文处理技术要落后很大一段距离,许多西文的处理方法中文不能直接采用,就是因为中文必需有分词这道工序。中文分词是其他中文信息处理的基础,搜索引擎只是中文分词的一个应用。其他的比如机器翻译(MT)、语音合成、自动分类、自动摘要、自动校对等等,都需要用到分词。因为中文需要分词,可能会影响一些研究,但同时也为一些企业带来机会,因为国外的计算机处理技术要想进入中国市场,首先也是要解决中文分词问题。
分词准确性对搜索引擎来说十分重要,但如果分词速度太慢,即使准确性再高,对于搜索引擎来说也是不可用的,因为搜索引擎需要处理数以亿计的网页,如果分词耗用的时间过长,会严重影响搜索引擎内容更新的速度。因此对于搜索引擎来说,分词的准确性和速度,二者都需要达到很高的要求。研究中文分词的大多是科研院校,清华、北大、哈工大、中科院、北京语言学院、山西大学、东北大学、IBM研究院、微软中国研究院等都有自己的研究队伍,而真正专业研究中文分词的商业公司除了海量科技以外,几乎没有了。科研院校研究的技术,大部分不能很快产品化,而一个专业公司的力量毕竟有限,看来中文分词技术要想更好的服务于更多的产品,还有很长一段路。
7.中文分词的常见项目
功能性能 功能描述:1.新词自动识别对词典中不存在的词,可以自动识别,对词典的依赖较小;2.词性输出分词结果中带有丰富的词性;3.动态词性输出分词结果中的词性并非固定,会根据不同的语境,赋予不同的词性;4.特殊词识别比如化学、药品等行业词汇,地名、品牌、媒体名等;5.智能歧义解决根据内部规则,智能解决常见分词歧义问题;6.多种编码识别自动识别各种单一编码,并支持混合编码;7.数词量词优化自动识别数量词; 性能介绍:处理器:AMD Athlon II x2 250 3GHZ单线程大于833KB/s,多线程安全。
一个PHP函数实现中文分词。使分词更容易,使用如下图: Paoding(庖丁解牛分词)基于Java的开源中文分词组件,提供lucene和solr 接口,具有极 高效率和 高扩展性。
引入隐喻,采用完全的面向对象设计,构思先进。高效率:在PIII 1G内存个人机器上,1秒可准确分词 100万汉字。
采用基于 不限制个数的词典文件对文章进行有效切分,使能够将对词汇分类定义。能够对未知的词汇进行合理解析。
仅支持Java语言。 MMSEG4J基于Java的开源中文分词组件,提供lucene和solr 接口:1.mmseg4j 用 Chih-Hao Tsai 的 MMSeg 算法实现的中文分词器,并实现 lucene 的 analyzer 和 solr 的TokenizerFactory 以方便在Lucene和Solr中使用。
2.MMSeg 算法有两种分词方法:Simple和Complex,都是基于正向最大匹配。Complex 加了四个规则过虑。
官方说:词语的正确识别率达到了 98.41%。mmseg4j 已经实现了这两种分词算法。
盘古分词是一个基于.net 平台的开源中文分词组件,提供lucene(.net 版本) 和HubbleDotNet的接口高效:Core Duo 1.8 GHz 下单线程 分词速度为 390K 字符每秒准确:盘古分词采用字典和统计结合的分词算法,分词准确率较高。功能:盘古分词提供中文人名识别,简繁混合分词,多元分词,英文词根化,强制一元分词,词频优先分词,停用词过滤,英文专名提取等一系列功能。
jcseg是使用Java开发的一个中文分词器,使用流行的mmseg算法实现。 1。
mmseg四种过滤算法,分词准确率达到了98.4%以上。2。
支持自定义词库。在lexicon文件夹下,可以随便添加/删除/更改词库和词库内容,并且对词库进行了分类,词库整合了《现代汉语词典》和cc-cedict辞典。
3。词条拼音和同义词支持,jcseg为所有词条标注了拼音,并且词条可以添加同义词集合,jcseg会自动将拼音和同义词加入到分词结果中。
4。中文数字和分数识别,例如:"四五十个人都来了,三十分之一。
"中的"四五十"和"三十分之一",并且jcseg会自动将其转换为对应的阿拉伯数字。5。
支持中英混合词的识别。例如:B超,x射线。
6。支持基本单字单位的识别,例如2012年。
7。良好的英文支持,自动识别电子邮件,网址,分数,小数,百分数……。
8。智能圆角半角转换处理。
9。特殊字母识别:例如:Ⅰ,Ⅱ10。
特殊数字识别:例如:①,⑩11。配对标点内容提取:例如:最好的Java书《java编程思想》,‘畅想杯黑客技术大赛’,被《,‘,“,『标点标记的内容。
12。智能中文人名识别。
中文人名识别正确率达94%以上。jcseg佩带了jcseg.properties配置文档,使用文本编辑器就可以自主的编辑其选项,配置适合不同应用场合的分词应用。
例如:最大匹配分词数,是否开启中文人名识别,是否载入词条拼音,是否载入词条同义词……。 friso是使用c语言开发的一个中文分词器,使用流行的mmseg算法实现。
完全基于模块化设计和实现,可以很方便的植入到其他程序中,例如:MySQL,PHP等。并且提供了一个php中文分词扩展robbe。
1。只支持UTF-8编码。
【源码无需修改就能在各种平台下编译使用,加载完20万的词条,内存占用稳定为14M。】。
2。mmseg四种过滤算法,分词准确率达到了98.41%。
3。支持自定义词库。
在dict文件夹下,可以随便添加/删除/更改词库和词库词条,并且对词库进行了分类。4。
词库使用了friso的Java版本jcseg的简化词库。5。
支持中英混合词的识别。例如:c语言,IC卡。
7。很好的英文支持,电子邮件,网址,小数,分数,百分数。
8。支持阿拉伯数字基本单字单位的识别,例如2012年,5吨,120斤。
9。自动英文圆角/半角,大写/小写转换。
并且具有很高的分词速度:简单模式:3.7M/秒,复杂模式:1.8M/秒。
8.什么是汉语分词
分词的提出和定义
汉语文本是基于单字的,汉语的书面表达方式也是以汉字作为最小单位的,词与词之间没有显性的界限标志,因此分词是汉语文本分析处理中首先要解决的问题
添加合适的显性的词语边界标志使得所形成的词串反映句子的本意,这个过程就是通常所说的分词
~~~~~~~~~~~~~~~~~~~~~~~
分词的意义
正确的机器自动分词是正确的中文信息处理的基础
~~~~~~~~~~~~~~~~~~~~~~~
文本检索
和服 | 务 | 于三日后裁制完毕,并呈送将军府中。
王府饭店的设施 | 和 | 服务 | 是一流的。如果不分词或者“和服务”分词有误,都会导致荒谬的检索结果。
文语转换
他们是来 | 查 | 金泰 | 撞人那件事的。(“查”读音为cha)
行侠仗义的 | 查金泰 | 远近闻名。(“查”读音为zha)
~~~~~~~~~~~~~~~~~~~~~~~
分词面临的主要难题
如何面向大规模开放应用是汉语分词研究亟待解决的主要问题
如何识别未登录词
如何低廉地获取语言学知识
词语边界歧义处理
实时性应用中的效率问题
~~~~~~~~~~~~~~~~~~~~~~~
分词歧义
交集型切分歧义
组合型切分歧义
~~~~~~~~~~~~~~~~~~~~~~~
分词规范
词是自然语言的一种客观存在
汉语书写过程中并不分词连写,对词组和词、单字语素和单字词的划分因人而异,甚至因时而异
汉语信息处理现在需要制订统一的分词标准,否则将严重影响计算机的处理
《信息处理用现代汉语分词规范及自动分词方法》:结合紧密、使用频繁
~~~~~~~~~~~~~~~~~~~~~~~
具体的分词标准实例
二字或三字词,以及结合紧密、使用稳定的:发展 可爱 红旗 对不起 自行车 青霉素
四字成语一律为分词单位:胸有成竹 欣欣向荣
四字词或结合紧密、使用稳定的四字词组:社会主义 春夏秋冬 由此可见
五字和五字以上的谚语、格言等,分开后如不违背原有组合的意义,应予切分:
时间/就/是/生命/
失败/是/成功/之/母
结合紧密、使用稳定的词组则不予切分:不管三七二十一
惯用语和有转义的词或词组,在转义的语言环境下,一律为分词单位:
妇女能顶/半边天/
他真小气,象个/铁公鸡/
略语一律为分词单位:科技 奥运会 工农业
分词单位加形成儿化音的“儿” :花儿 悄悄儿 玩儿
阿拉伯数字等,仍保留原有形式:1234 7890
现代汉语中其它语言的汉字音译外来词,不予切分:巧克力 吉普
不同的语言环境中的同形异构现象,按照具体语言环境的语义进行切分:
把/手/抬起来
这个/把手/是木制的