哪些数据要进行因子分析方法(常用的数据分析方法)
1.常用的数据分析方法有哪些
数据分析落实到实处,一般就是围绕用户漏斗展开的。也就是人们常说的访问-激活-留存-交易-推荐。
这核心的5步会有不同维度的细分。
获客:来源、渠道、关键字、着陆页、地域、设备、访问时间、跳出率、访问深度、停留时间、新客量等等;
激活:DAU(日活跃用户)、MAU(月活跃用户)
留存:日留存率、周留存率、月留存率
交易:订单量、订单金额、LTV
推荐:是否传播(k>1)
需要获取以上数据,可以通过ptengine通过漏斗细分得到可视化图表。一般来讲,同比(本周和上周)、环比(本月第一周和上月第一周)、定基比(所有数据和当年第一周)即可获得数据的变化情况。
以上,其实不用很专业也能做好数据分析,获取数据并不难,难的是你能洞察数据背后的意义。
2.因子分析法的分析步骤
因子分析的核心问题有两个:一是如何构造因子变量;二是如何对因子变量进行命名解释。因此,因子分析的基本步骤和解决思路就是围绕这两个核心问题展开的。
(i)因子分析常常有以下四个基本步骤:
⑴确认待分析的原变量是否适合作因子分析。
⑵构造因子变量。
⑶利用旋转方法使因子变量更具有可解释性。
⑷计算因子变量得分。
(ii)因子分析的计算过程:
⑴将原始数据标准化,以消除变量间在数量级和量纲上的不同。
⑵求标准化数据的相关矩阵;
⑶求相关矩阵的特征值和特征向量;
⑷计算方差贡献率与累积方差贡献率;
⑸确定因子:
设F1,F2,…, Fp为p个因子,其中前m个因子包含的数据信息总量(即其累积贡献率)不低于80%时,可取前m个因子来反映原评价指标;
⑹因子旋转:
若所得的m个因子无法确定或其实际意义不是很明显,这时需将因子进行旋转以获得较为明显的实际含义。
⑺用原指标的线性组合来求各因子得分:
采用回归估计法,Bartlett估计法或Thomson估计法计算因子得分。
⑻综合得分
以各因子的方差贡献率为权,由各因子的线性组合得到综合评价指标函数。
F = (w1F1+w2F2+…+wmFm)/(w1+w2+…+wm )
此处wi为旋转前或旋转后因子的方差贡献率。
⑼得分排序:利用综合得分可以得到得分名次。
在采用多元统计分析技术进行数据处理、建立宏观或微观系统模型时,需要研究以下几个方面的问题:
· 简化系统结构,探讨系统内核。可采用主成分分析、因子分析、对应分析等方法,在众多因素中找出各个变量最佳的子集合,从子集合所包含的信息描述多变量的系统结果及各个因子对系统的影响。“从树木看森林”,抓住主要矛盾,把握主要矛盾的主要方面,舍弃次要因素,以简化系统的结构,认识系统的内核。
· 构造预测模型,进行预报控制。在自然和社会科学领域的科研与生产中,探索多变量系统运动的客观规律及其与外部环境的关系,进行预测预报,以实现对系统的最优控制,是应用多元统计分析技术的主要目的。在多元分析中,用于预报控制的模型有两大类。一类是预测预报模型,通常采用多元线性回归或逐步回归分析、判别分析、双重筛选逐步回归分析等建模技术。另一类是描述性模型,通常采用聚类分析的建模技术。
· 进行数值分类,构造分类模式。在多变量系统的分析中,往往需要将系统性质相似的事物或现象归为一类。以便找出它们之间的联系和内在规律性。过去许多研究多是按单因素进行定性处理,以致处理结果反映不出系统的总的特征。进行数值分类,构造分类模式一般采用聚类分析和判别分析技术。
如何选择适当的方法来解决实际问题,需要对问题进行综合考虑。对一个问题可以综合运用多种统计方法进行分析。例如一个预报模型的建立,可先根据有关生物学、生态学原理,确定理论模型和试验设计;根据试验结果,收集试验资料;对资料进行初步提炼;然后应用统计分析方法(如相关分析、逐步回归分析、主成分分析等)研究各个变量之间的相关性,选择最佳的变量子集合;在此基础上构造预报模型,最后对模型进行诊断和优化处理,并应用于生产实际。
3.数据分析方法有哪些
一、描述性统计
描述性统计是一类统计方法的汇总,揭示了数据分布特性。它主要包括数据的频数分析、数据的集中趋势分析、数据离散程度分析、数据的分布以及一些基本的统计图形。
1、缺失值填充:常用方法有剔除法、均值法、决策树法。
2、正态性检验:很多统计方法都要求数值服从或近似服从正态分布,所以在做数据分析之前需要进行正态性检验。常用方法:非参数检验的K-量检验、P-P图、Q-Q图、W检验、动差法。
二、回归分析
回归分析是应用极其广泛的数据分析方法之一。它基于观测数据建立变量间适当的依赖关系,以分析数据内在规律。
1. 一元线性分析
只有一个自变量X与因变量Y有关,X与Y都必须是连续型变量,因变量Y或其残差必须服从正态分布。
2. 多元线性回归分析
使用条件:分析多个自变量X与因变量Y的关系,X与Y都必须是连续型变量,因变量Y或其残差必须服从正态分布。
3.Logistic回归分析
线性回归模型要求因变量是连续的正态分布变量,且自变量和因变量呈线性关系,而Logistic回归模型对因变量的分布没有要求,一般用于因变量是离散时的情况。
4. 其他回归方法:非线性回归、有序回归、Probit回归、加权回归等。
三、方差分析
使用条件:各样本须是相互独立的随机样本;各样本来自正态分布总体;各总体方差相等。
1. 单因素方差分析:一项试验只有一个影响因素,或者存在多个影响因素时,只分析一个因素与响应变量的关系。
2. 多因素有交互方差分析:一顼实验有多个影响因素,分析多个影响因素与响应变量的关系,同时考虑多个影响因素之间的关系
3. 多因素无交互方差分析:分析多个影响因素与响应变量的关系,但是影响因素之间没有影响关系或忽略影响关系
4. 协方差分祈:传统的方差分析存在明显的弊端,无法控制分析中存在的某些随机因素,降低了分析结果的准确度。协方差分析主要是在排除了协变量的影响后再对修正后的主效应进行方差分析,是将线性回归与方差分析结合起来的一种分析方法。
四、假设检验
1. 参数检验
参数检验是在已知总体分布的条件下(一股要求总体服从正态分布)对一些主要的参数(如均值、百分数、方差、相关系数等)进行的检验 。
2. 非参数检验
非参数检验则不考虑总体分布是否已知,常常也不是针对总体参数,而是针对总体的某些一般性假设(如总体分布的位罝是否相同,总体分布是否正态)进行检验。
适用情况:顺序类型的数据资料,这类数据的分布形态一般是未知的。
1)虽然是连续数据,但总体分布形态未知或者非正态;
2)总体分布虽然正态,数据也是连续类型,但样本容量极小,如10以下;
主要方法包括:卡方检验、秩和检验、二项检验、游程检验、K-量检验等。
4.常用的数据分析方法有什么
去百度文库,查看完整内容>
内容来自用户:蒋上树
常用数据分析方法有那些
文章来源:ECP数据分析时间:2013/6/28 13:35:06发布者:常用数据分析(关注:554)
标签:本文包括:
常用数据分析方法:聚类分析、因子分析、相关分析、对应分析、回归分析、方差分析;
问卷调查常用数据分析方法:描述性统计分析、探索性因素分析、Cronbach'a信度系数分析、结构方程模型分析(structural equations modeling)。
数据分析常用的图表方法:柏拉图(排列图)、直方图(Histogram)、散点图(scatter diagram)、鱼骨图(Ishikawa)、FMEA、点图、柱状图、雷达图、趋势图。
数据分析统计工具:SPSS、minitab、JMP。
常用数据分析方法:
1、聚类分析(Cluster Analysis)
聚类分析指将物理或抽象对象的集合分组成为由类似的对象组成的多个类的分析过程。聚类是将数据分类到不同的类或者簇这样的一个过程,所以同一个簇中的对象有很大的相似性,而不同簇间的对象有很大的相异性。聚类分析是一种探索性的分析,在分类的过程中,人们不必事先给出一个分类的标准,聚类分析能够从样本数据出发,自动进行分类。聚类分析所使用方法的不同,常常会得到不同的结论。不同研究者对于同一组数据进行聚类分析,所得到的聚类数未必一致。
2、因子分析(Factor Analysis)
因子分析是指研究从变量群中提取共性因子的统计技术。因子分析就是从大量的数据中寻找内在的联系,减少决策的困难。相关分析(直方图JMP
5.什么是spss因子分析方法
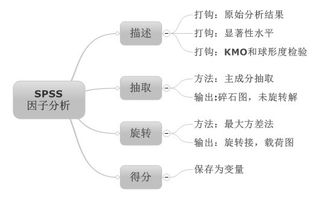
本来想给你截图的,可是传不上来,我就简单说一下哈。
首先你得进行一次预计算,选择菜单里分析——降维——因子分析,跳出主面板,把想分析的变量选到变量框里,然后点确定。这时候输出窗口里会只有一个或两个图表。其中有一个图表是主成分的方差贡献。这个图表里你要找到两个相邻的列(应该是第三列和第四列),其中前一个列指的是单个因子对方差的贡献率,后一个是因子累计贡献率。也就是说前一个列里边数值相加等于100,后一个列里边数值递增,最后一个等于100。假如前一个列里是60,30,10,那么后一列里就是60,90,100.两个列之间有一个和的关系。找到这两个列以后,你要找使得累计贡献率达到百分之八十的那个数。这个表的第一列是1,2,3,等等,它代表第几个因子,比如3指的那行就包括第三个因子的方差贡献率,累积到第三个因子的方差贡献率这两个数据。你要找到累计到达百分之八十的那个因子是第几个因子,然后就按提取几个因子进行计算。
通过预计算知道了提取几个因子之后,就开始正式计算。再次打开因子分析的主面板,在最右边一共有五个选项,分别是描述,抽取,旋转,得分,选项。这五个在预计算里边没有用,但是现在要用了。点继续。
点击描述,在对话框里选上初始变量分析,kmo统计量及bartlett球形检验这两个选项,(注意,kmo和bartlett是一个选项,选项名就是很长)这一步是用来判断变量是否适于进行因子分析的。
点击抽取,对话框里最上边的方法就选主成分,分析里选上相关性矩阵,输出选上未旋转的因子解和碎石图两个选项,抽取里选择因子的固定数目,在要提取的因子后边填上你预计算里算出的因子数目。点继续。
旋转里边选最大方差法,输出旋转解。继续。
得分里边选保存为变量,方法为回归,显示因子得分系数矩阵也要打上勾。继续。
确定。
然后就可以分析结果了。
先看kmo和bartlett的结果,kmo统计量越接近1,变量相关性越强,因子分析效果越好。通常0.7以上为一般,0.5以下不能接受,就是不适合做因子分析。bartlett检验从检验相关矩阵出发,如果p值,就是sig,比较小的话,一般认为小于0.05,当然越小越好,就适于因子分析。
如果这两个检验都合格的话,才可以去写因子模型。
为了便于描述,假设我们有两个因子f1,f2,
旋转变换后的因子载荷矩阵会告诉你每个变量用因子表示的系数。比如变量x1=系数1*f1+系数2*f2,变量2以此类推。
因子得分系数矩阵会告诉你每个因子里各变量占得权重,比如f1=系数1*x1+系数2*x2+。
根据这个我们就能算出因子得分了。
因为之前选择了将因子保存为新变量,所以spss会直接保存两个因子得分为两个新变量,
然后我们不是有一个公式吗
总得分=因子1的方差贡献率*因子1的得分+因子2的方差贡献率*因子2的得分+。
根据这个公式计算一下就可以了。
用spss或者excel都可以。
希望能对你有帮助哦。
ppv课,大数据培训专家,最专业的大数据培训平台。为你提供最好的spss学习教程哦。
6.数据分析都有哪些方法
常用数据分析方法:聚类分析、因子分析、相关分析、对应分析、回归分析、方差分析; 问卷调查常用数据分析方法:描述性统计分析、探索性因素分析、Cronbach'a信度系数分析、结构方程模型分析(structural equations modeling) 。
数据分析常用的图表方法:柏拉图(排列图)、直方图(Histogram)、散点图(scatter diagram)、鱼骨图(Ishikawa)、FMEA、点图、柱状图、雷达图、趋势图。 数据分析统计工具:SPSS、minitab、JMP。