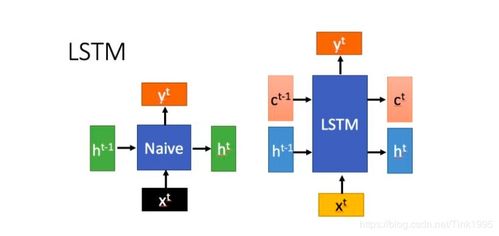
lstm能与哪些方法相结合(为什么LSTM在参数初始化时要使用SVD方法使参数正交)
1.为什么 LSTM 在参数初始化时要使用 SVD 方法使参数正交
首先,除了 orthogonal initialization 和 uniform initialization,现在常用的还有 Gaussian initialization。不常用的还有 identity initialization 和现在“已经被时代抛弃”的 pretraining with autoencoder。这些方法在不同的场景下都被人选择了。个人感觉,比较复杂的 LSTM 用 orthogonal initialization 的人比较多,而在 research paper 讨论一个小 task 时,我看到的大部分还是说用 uniform/Gaussian。这里可能的直观的原因是后者的 layer 和 magnitude 比较少/小。
说到 layer 比较少,其实我是想说,orthogonal initialization,个人认为对于 LSTM (deep, high-dimensitional, non-convex)比较有效的原因是,(1)可以很方便地减缓 gradient vanishing/exploding problem 和 activation functions 的 saturation。因为 orthogonal matrix 的所有 vectors 都是 orthonormal 的,也就是不仅 orthogonal,还 magnitude 为 1. 这样,在计算时候,乘上这个 matrix,就可以修正 vanishing 也可以重置 saturation。(2)这个问题应该是和 saddle point 有关系,复杂的 LSTM 受 saddle point structures 带来的各种问题更严重,而基于 SVD/QR 的 orthogonal initialization 可以 decouple networks 之间的依赖,消除 non-global minima。(3)当然还有这几种 initialization 都用来破坏 symmetry。
上面这是可被证实的,下面来点个人的猜测:这和 weight variation 也有关系。
综上,有些人觉得这几种方法没区别,有人觉得有,完全是 case-by-case。我个人在实践过程中,即使是小网络,也觉得有区别。
2.如何理解LSTM后接CRF
有一个答案给的是一篇acl2016的论文,采用的神经网络结构是 cnn + lstm +crf的经典架构,是一个很成熟的系统
目前来说,实体识别的应用领域,lstm+crf是一种标配了,短期内我认为只要在attention方面没有很大的突破,这一框架都不会变化
要理解为什么lstm后面要接crf层,首先应该理解的是crf的功能
题主问这个问题,想必是明白lstm的output,我们姑且不讨论原理,lstm在序列标注的问题,落实到题主说的ner,也就是一个seq2seq,在英文中,可以是对每一个input的单词,对例如bieo的四个标签进行预测,假设当前输出的事100个words,那个输出的就是100*4的一个概率预测,这应该就是答主的疑惑,我们直接用一个分类器,四个里面选一个就好了,为什么要再接crf呢?
那么,我们首先考虑我们使用lstm的初衷,就是为了考虑上下文来分析当前的tag标注,其实crf也是接近的原理,crf意会一点的描述其实有点像一张概率图,在single crf中,你需要做的是尽可能的对每个对象挖掘多的特征,然后学习他们之间的一种“衔接”关系,在lstm后面加上crf,相当于对lstm抽象过的一种语言关系来进行crf训练,可以使用那篇论文上的likehood函数,当然使用labelwise的也可以,这也属于调参的一部分
总之我个人的理解,crf相当于对lstm信息的再利用,利用效率高于一个简单的分类器,实际情况也适合这一点,题主不妨找个实例测测玩玩,也就明白了
3.为什么 LSTM 在参数初始化时要使用 SVD 方法使参数正交
首先,除了 orthogonal initialization 和 uniform initialization,现在常用的还有 Gaussian initialization。
不常用的还有 identity initialization 和现在“已经被时代抛弃”的 pretraining with autoencoder。这些方法在不同的场景下都被人选择了。
个人感觉,比较复杂的 LSTM 用 orthogonal initialization 的人比较多,而在 research paper 讨论一个小 task 时,我看到的大部分还是说用 uniform/Gaussian。这里可能的直观的原因是后者的 layer 和 magnitude 比较少/小。
说到 layer 比较少,其实我是想说,orthogonal initialization,个人认为对于 LSTM (deep, high-dimensitional, non-convex)比较有效的原因是,(1)可以很方便地减缓 gradient vanishing/exploding problem 和 activation functions 的 saturation。因为 orthogonal matrix 的所有 vectors 都是 orthonormal 的,也就是不仅 orthogonal,还 magnitude 为 1. 这样,在计算时候,乘上这个 matrix,就可以修正 vanishing 也可以重置 saturation。
(2)这个问题应该是和 saddle point 有关系,复杂的 LSTM 受 saddle point structures 带来的各种问题更严重,而基于 SVD/QR 的 orthogonal initialization 可以 decouple networks 之间的依赖,消除 non-global minima。(3)当然还有这几种 initialization 都用来破坏 symmetry。
上面这是可被证实的,下面来点个人的猜测:这和 weight variation 也有关系。综上,有些人觉得这几种方法没区别,有人觉得有,完全是 case-by-case。
我个人在实践过程中,即使是小网络,也觉得有区别。
4.如何理解LSTM后接CRF
有一个答案给的是一篇acl2016的论文,采用的神经网络结构是 cnn + lstm +crf的经典架构,是一个很成熟的系统目前来说,实体识别的应用领域,lstm+crf是一种标配了,短期内我认为只要在attention方面没有很大的突破,这一框架都不会变化要理解为什么lstm后面要接crf层,首先应该理解的是crf的功能题主问这个问题,想必是明白lstm的output,我们姑且不讨论原理,lstm在序列标注的问题,落实到题主说的ner,也就是一个seq2seq,在英文中,可以是对每一个input的单词,对例如bieo的四个标签进行预测,假设当前输出的事100个words,那个输出的就是100*4的一个概率预测,这应该就是答主的疑惑,我们直接用一个分类器,四个里面选一个就好了,为什么要再接crf呢?那么,我们首先考虑我们使用lstm的初衷,就是为了考虑上下文来分析当前的tag标注,其实crf也是接近的原理,crf意会一点的描述其实有点像一张概率图,在single crf中,你需要做的是尽可能的对每个对象挖掘多的特征,然后学习他们之间的一种“衔接”关系,在lstm后面加上crf,相当于对lstm抽象过的一种语言关系来进行crf训练,可以使用那篇论文上的likehood函数,当然使用labelwise的也可以,这也属于调参的一部分总之我个人的理解,crf相当于对lstm信息的再利用,利用效率高于一个简单的分类器,实际情况也适合这一点,题主不妨找个实例测测玩玩,也就明白了。